
Backup to Object Storage ist in aller Munde, ganz so einfach ist es aber dann doch nicht immer. In dem Artikel werden wir einen Blick hinter die Kulissen werfen. In unseren Projekten kamen immer wieder ähnliche Fragen auf, welche ich heute aufgreifen möchte, unteranderem:
- Wie werden die Daten im S3 abgelegt?
- Sind die Daten überlebensfähig, wenn mein Backup Server nicht mehr da ist?
- Was passiert, wenn jemand die Daten direkt aus dem S3 löscht?
- Verhält sich das Object Storage Repository wie ein „normales“ Repository?
Unser Test Setup besteht aus folgenden Komponenten:
Veeam v12.0.0.1420
NetApp StorageGRID in Version 11.7.0.4
Schritt 1: Erstellen des Buckets
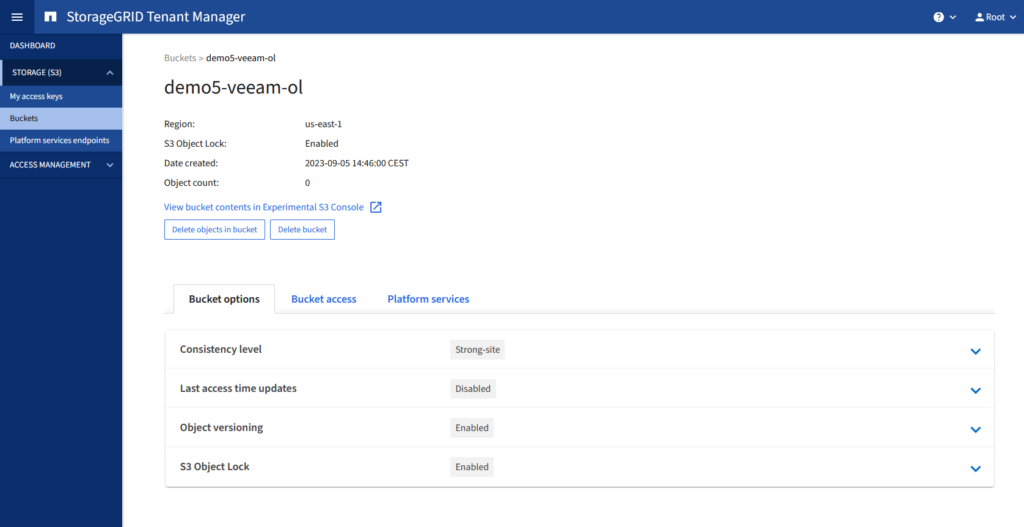
Los geht’s – wir starten mit dem Bucket, davor muss jedoch Object Lock auf dem GRID global aktiviert werden, falls noch nicht geschehen.
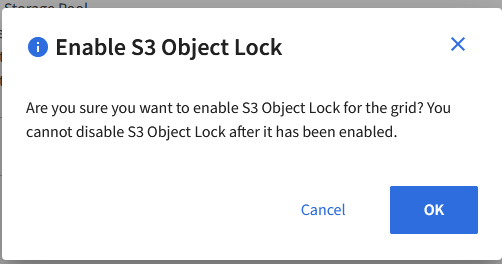
Der wohl wichtigste Punkt ist, dass Object Lock direkt beim Erstellen des Buckets aktiviert werden muss, eine nachträgliche Aktivierung ist nicht möglich. Das scheint auch bei anderen Herstellern von Object Storage üblich zu sein, jedenfalls haben sich andere Systeme auch so verhalten. Am einfachsten geht das über den Tenant Manager. Wichtig ist, dass neben Object Lock auch Versioning aktiviert werden muss, was Storage Grid aber ohnehin erzwingt. Infos von Veeam dazu gibt es hier.
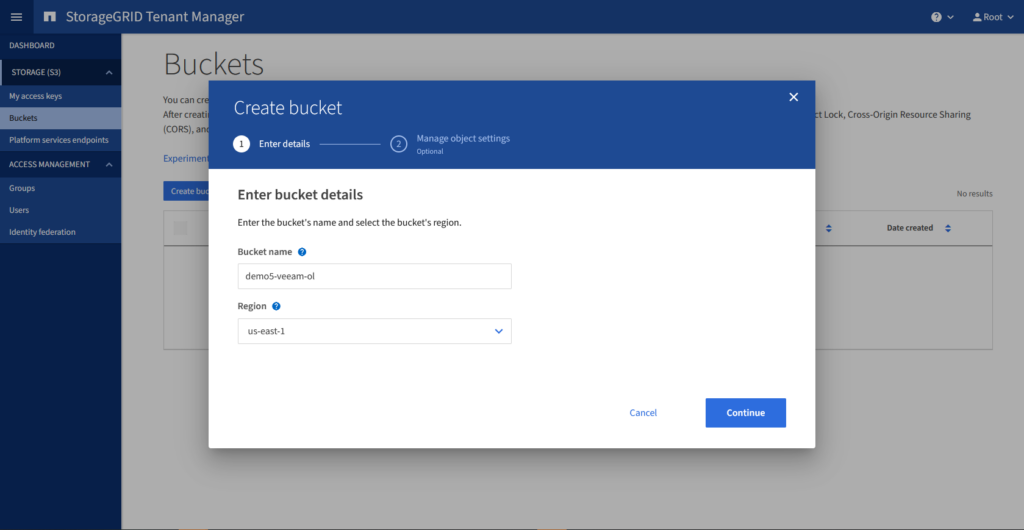
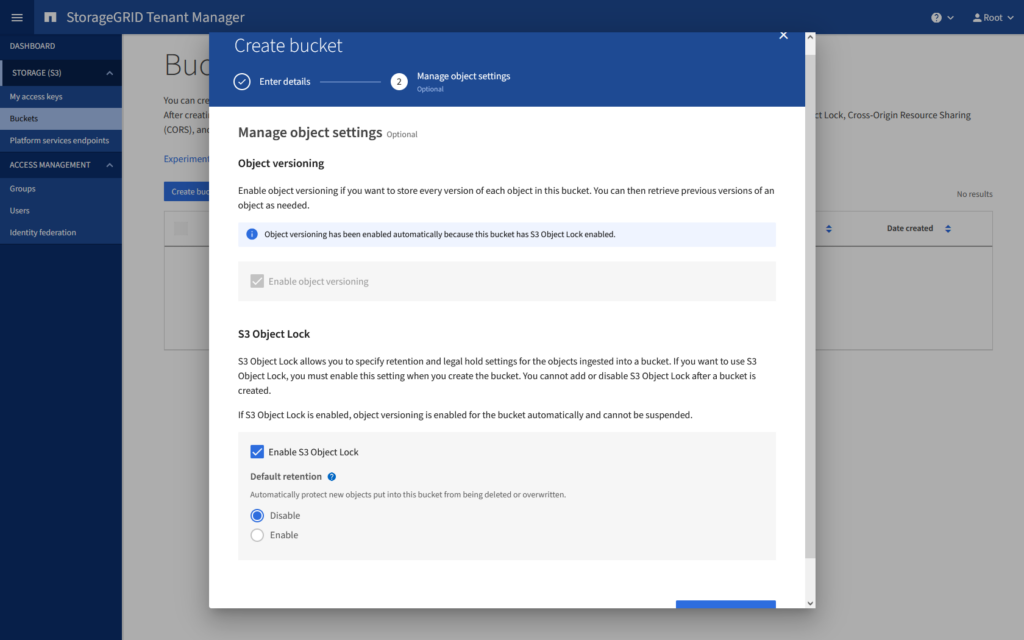
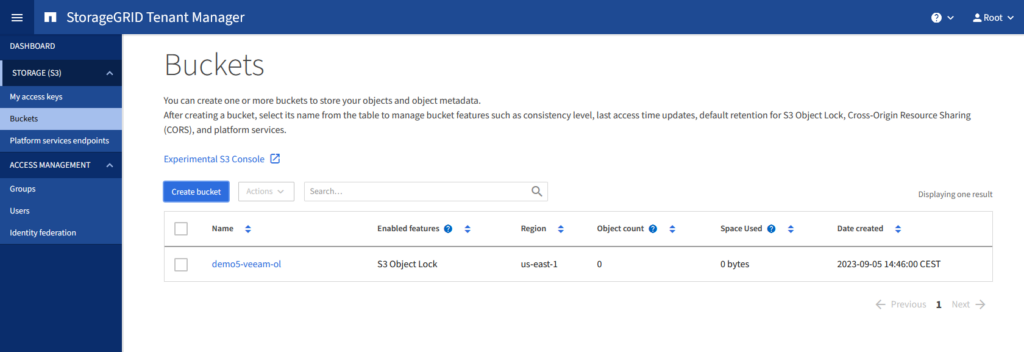
Nach dem Anlegen des Buckets gibt es einen ganz wichtigen Punkt bei der Benutzung von StorageGRID in Kombination mit Veeam v12. Das Consistency Level muss je nach Design auf Strong-site oder Strong-global gesetzt werden. Die Einstellung kann ebenfalls im Tenant Manager vorgenommen werden.
„Strong Consistency must be explicitly enabled in the configuration settings to meet the compatibility requirements for Veeam Backup and Replication v12.“
Dieser Hinweis befindet sich im offiziellen Post von Veeam.
Schritt 2: Repository in Veeam
Das Bucket muss nun in Veeam eingebunden werden. Hierfür geben wir die Adresse des Object Storages und die Zugangsdaten ein.
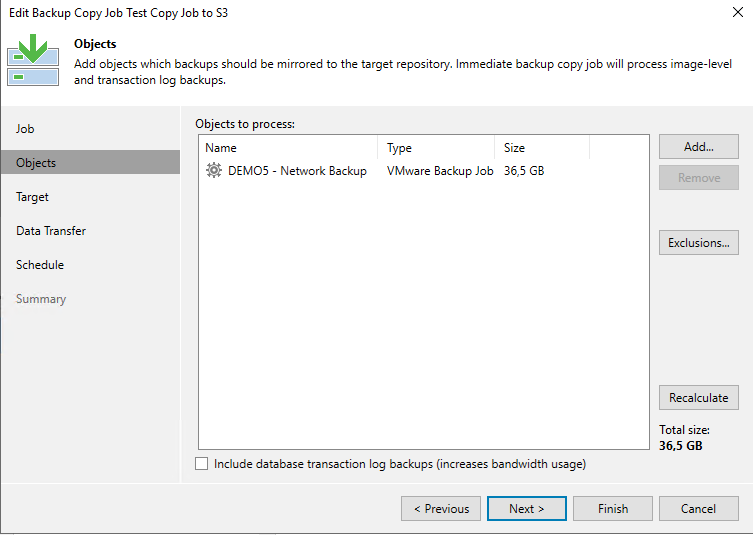
Anschließend konfigurieren wir einen Copy Job auf das neu angelegte Repository und lassen diesen direkt starten.
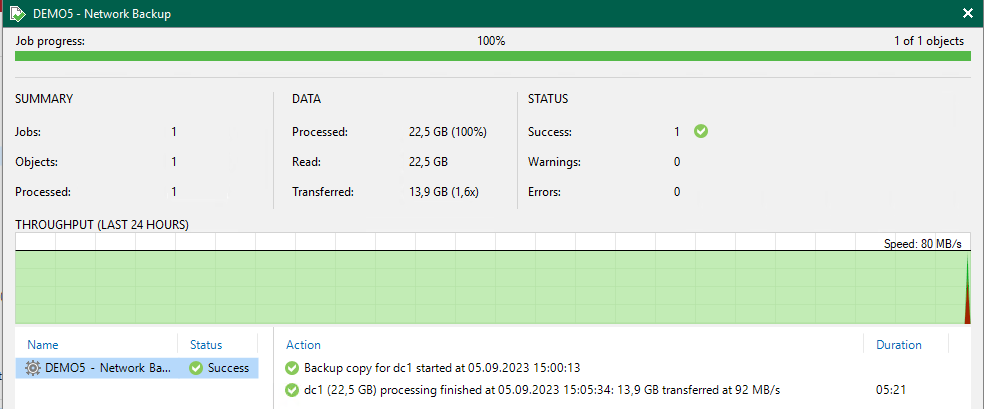
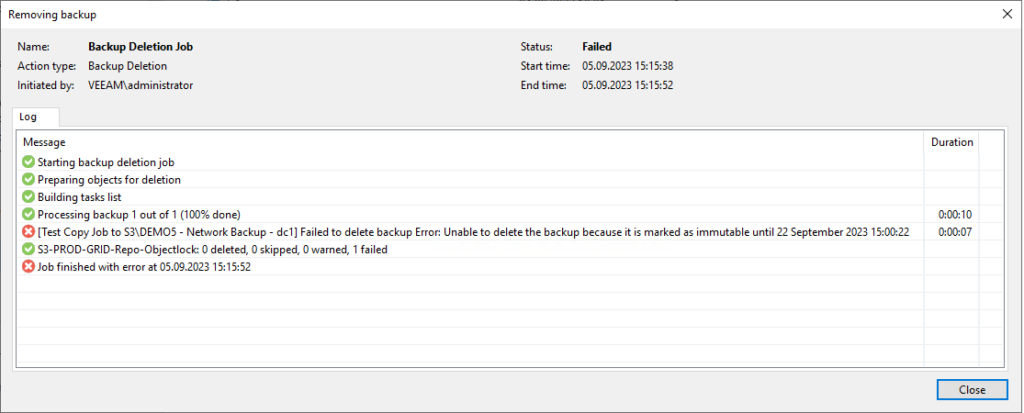
Versucht man diese Daten nun über Veeam zu löschen, tritt das erwartete Ergebnis ein, Veeam verweigert korrekterweise das Löschen der Backups.
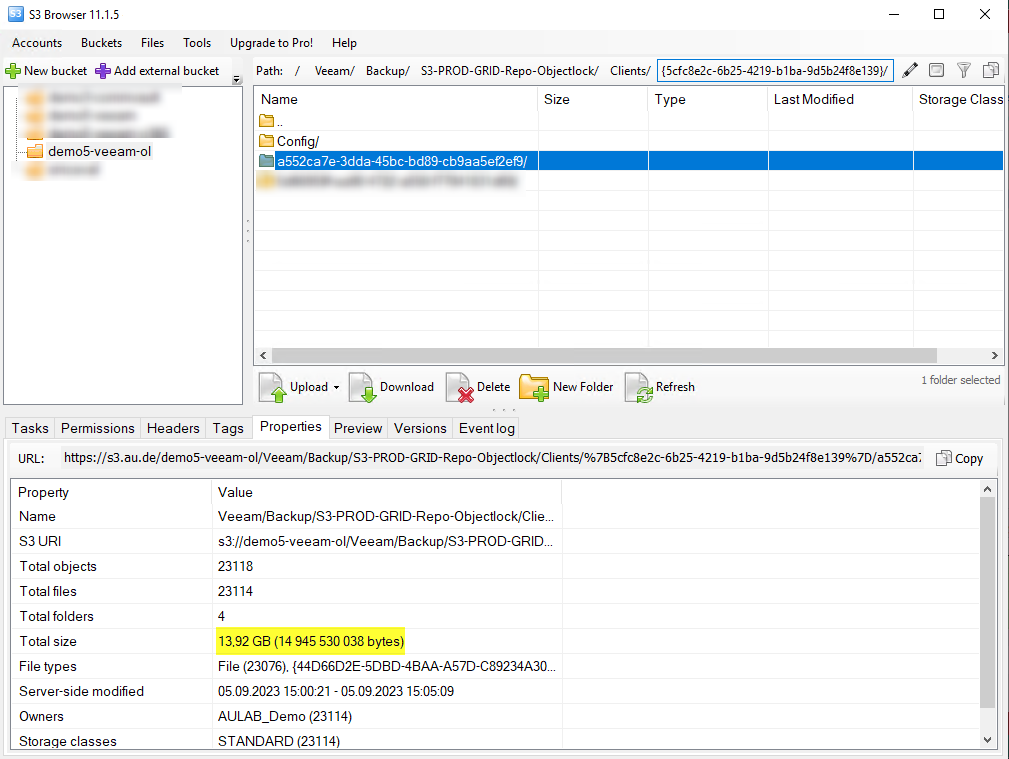
Schritt 3: Blick auf die Daten im S3 Browser
Wie verhält sich das Ganze nun aber direkt mit einem S3 Browser? Pro Job wird eine Ordner ID generiert, hier landen die eigentlichen Backup Daten. Man sieht hier ganz gut, dass die Größe des Ordners zu der gesicherten Datenmenge in Veeam passt.
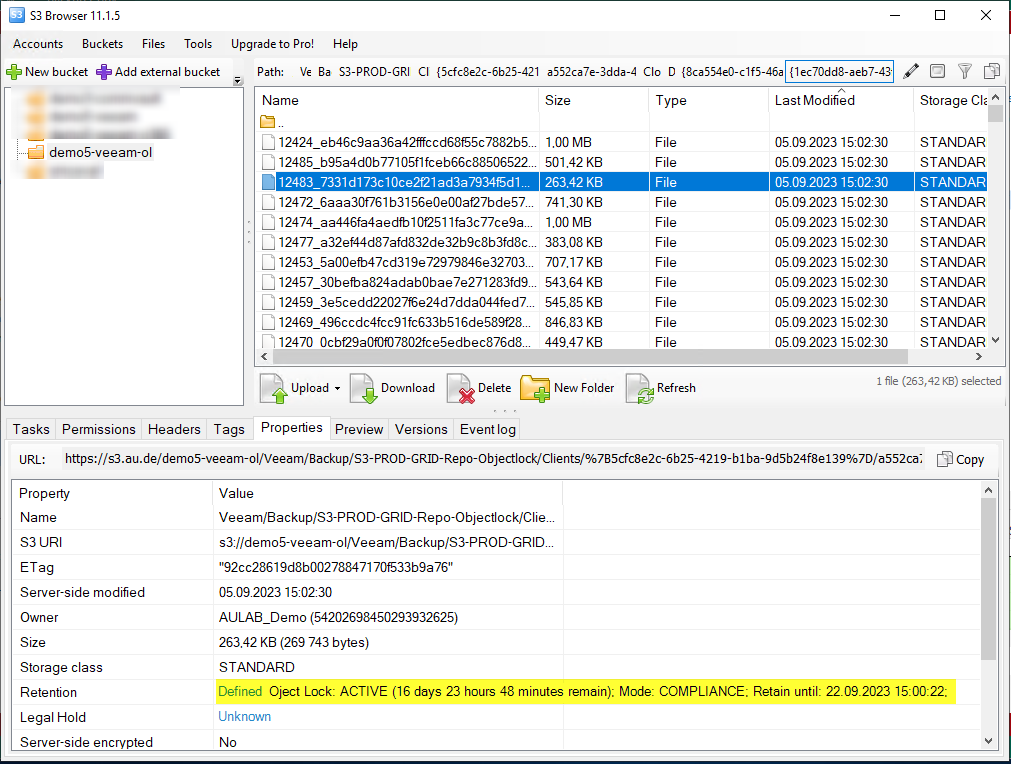
Die eigentlichen Daten findet man in vielen Unterordnern, die Dateistruktur ist aber definitiv nicht menschenlesbar. Veeam arbeitet per Default mit einer Blocksize von 1MB „pre efficiency“, heißt im Ergebnis sind das sehr viele Dateien mit 0KB – 1MB; je nachdem, wie gut die Daten komprimiert werden konnten.
Hier sieht man bereits, dass Object Lock erfolgreich angewendet werden konnte – der Timestamp entspricht dem Timestamp in der Veeam GUI.
Die wohl meist gestellte Frage ist: „Was ist, wenn jemand Zugang zu meinem S3 Speicher bekommt, ich habe das versucht und konnte die Daten löschen! Haben wir etwas falsch konfiguriert, haben wir einen Bug gefunden?“
Genau das habe ich auch getan und den kompletten Ordner gelöscht, und zwar erfolgreich. Die gute Nachricht vorweg – Works as designed!
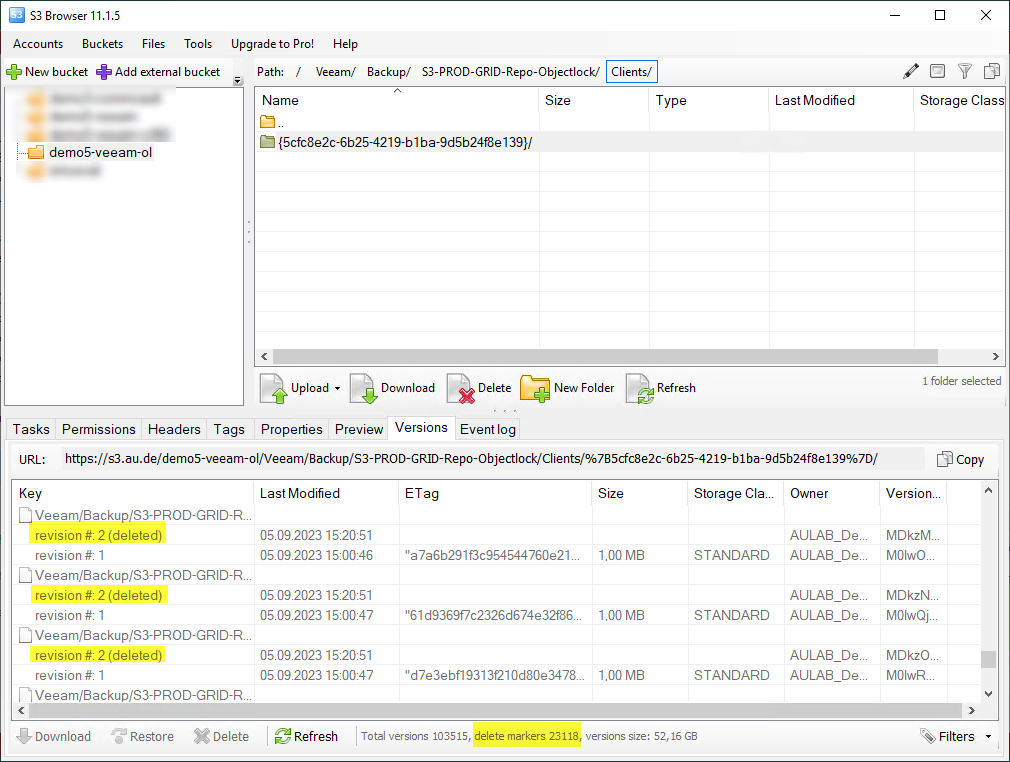
Genau an diesem Punkt kommt das Versioning Feature zum Einsatz. Nicht nur für Daten, die bereits überschrieben wurden, wird eine neue Version des Objekts erzeugt, sondern auch für gelöschte Objekte. Gelöschte Objekte bekommen dann einen „delete maker“ und sind damit in den üblichen GUIs nicht mehr sichtbar, aber eben nach wie vor verfügbar. Die eigentlich ObjectLock-geschützten Daten sind als “non-current versions” noch immer vorhanden. Der Trick ist, dass sich die Applikation neben der ObjectID (Dateiname) auch die VersionID merkt, um auf die richtige Version zuzugreifen.
Und wer genau aufgepasst hat, dem fällt auf, dass die „delete markers 23118“ genau der Anzahl der Objekte von oben entsprechen.
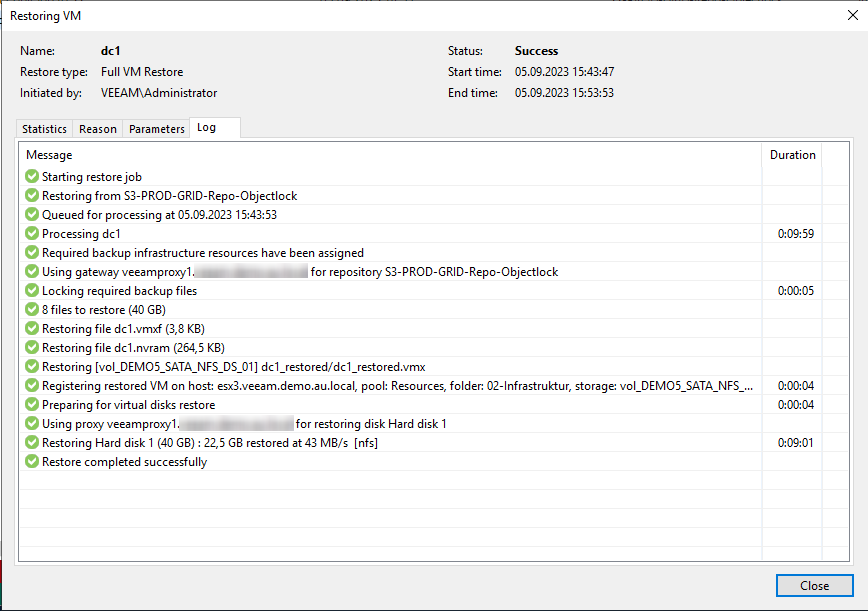
Schritt 4: Restore der gelöschten Daten
Um nun den Beweis anzutreten, dass trotz gelöschter Objekte noch alles funktioniert, machen wir einen Restore der Daten aus dem Object Storage. Ich entscheide mich für einen Full VM Restore welcher nach einiger Zeit auch erfolgreich abgeschlossen wird.
Nun bin ich zwei Antworten schuldig geblieben…
- Sind die Daten überlebensfähig wenn mein Backup Server nicht mehr da ist?
Klares ja! Per Design sind alle Veeam Backups überlebensfähig, auch wenn die Konfiguration des Backup Servers nicht mehr zur Verfügung steht. Gibt es diese z.B. in Form eines Configuration Backups, noch ist dies jedoch hilfreich.
- Verhält sich das Object Storage Repository wie ein „normales“ Repository?
Ja – mit der Einführung von Veeam v12 wurde in fast allen Bereichen Feature Parität erreicht. Wie so oft gibt es noch kleine Detaileinschränkungen, die jedoch nicht die breite Masse treffen.