
Das gesamte Routing im Internet läuft über das altbewährte BGP Protokoll. Obwohl BGP schon relativ alt ist, hat es sich bis heute gehalten und damit bewiesen, wie skalierbar und zuverlässig dieses Protokoll ist. Aus diesem Grund wird es inzwischen auch schon immer häufiger im Rechenzentrum eingesetzt, um das Routing dort zu steuern und zu verwalten.
Auch ONTAP unterstützt seit Version 9.5 BGP als Routing-Protokoll. Die Idee dahinter ist, dass ONTAP mit den Routern im RZ über BGP kommuniziert, und IP-Adressen von SVMs darüber annonciert. Dadurch wird man unabhängig von Layer-2 Konstrukten (VLANs, Interface-Gruppen, etc.) und kann auch in größeren gerouteten Netzen hochverfügbare Dienste zur Verfügung stellen.
In diesem Beitrag werfen wir einen kurzen Blick auf die Konfiguration und Implementierung dieses Protokolls.
Folgende Skizze beschreibt das implementierte Szenario. Auf die Details werden wir in den nächsten Absätzen ein wenig eingehen.
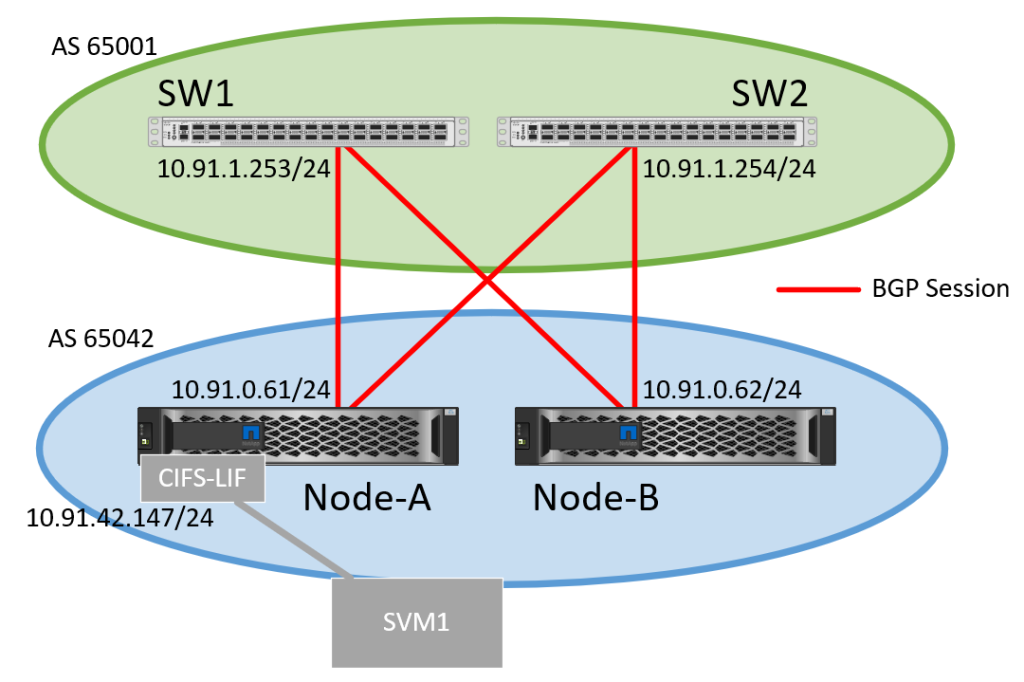
Konfiguration der Routing-Switches
Als Erstes benötigt man natürlich ein paar BGP-fähige Router. Bei uns im Lab sind das Cisco Nexus 3600 Switches, im Bild mit SW1 und SW2 bezeichnet. Auf diesen wird der BGP Routing-Prozess konfiguriert, die beiden Nexus werden wechselseitig mit iBGP Sessions verbunden und bekommen jeweils zwei eBGP Sessions auf die (noch zu konfigurierenden) VIP Interfaces der beiden NetApp Controller. Hier ist die Konfiguration des ersten Switches:
sw1(config)# router bgp 65001
sw1(config-router)# router-id 10.91.1.253
sw1(config-router)# log-neighbor-changes
sw1(config-router)# address-family ipv4 unicast
sw1(config-router-af)# maximum-paths 2
sw1(config-router-af)# neighbor 10.91.1.254 remote-as 65001
sw1(config-router-neighbor)# address-family ipv4 unicast
sw1(config-router-neighbor)# neighbor 10.91.0.61 remote-as 65042
sw1(config-router-neighbor)# disable-connected-check
sw1(config-router-neighbor)# address-family ipv4 unicast
sw1(config-router-neighbor)# neighbor 10.91.0.62 remote-as 65042
sw1(config-router-neighbor)# disable-connected-check
sw1(config-router-neighbor)# address-family ipv4 unicastWir nutzen hier disable-connected-check, da wir das BGP Peering über geroutete IP-Adressen machen und uns damit die Konfiguration von eBGP-Multihop sparen. Die Konfiguration des zweiten Switches läuft analog.
Anschließend sind die iBGP Relationships online, die eBGP Relationships natürlich bisher nicht, dazu müssen wir erst BGP im ONTAP konfigurieren:
sw1# show ip bgp summary
BGP summary information for VRF default, address family IPv4 Unicast
BGP router identifier 10.91.1.253, local AS number 65001
BGP table version is 202, IPv4 Unicast config peers 3, capable peers 1
2 network entries and 2 paths using 336 bytes of memory
BGP attribute entries [4/544], BGP AS path entries [2/12]
BGP community entries [0/0], BGP clusterlist entries [0/0]
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
10.91.0.61 4 65042 0 0 0 0 0 2d Idle
10.91.0.62 4 65042 0 0 0 0 0 2d Idle
10.91.1.254 4 65001 12 12 3 0 0 2d 1
Im ONTAP gliedert sich die Konfiguration von BGP in 4 Schritte:
- Erstellen einer BGP Konfiguration
- Erstellen von BGP Interfaces auf allen Nodes
- Erstellen der eBGP Peerings (Peer-Groups)
- Erstellen eines LIFs, welches per BGP announced wird
Erstellen der BGP Konfiguration
Die BGP Konfiguration definiert primär die AS Nummer und die Router ID der jeweiligen Nodes. Als Router-ID nehmen wir hier die IP-Adresse der jeweiligen BGP Interfaces.
cl1::> bgp config create -node cl1n1 -asn 65042 -router-id 10.91.0.61
cl1::> bgp config create -node cl1n2 -asn 65042 -router-id 10.91.0.62Erstellen von BGP Interfaces
Die BGP Interfaces werden benötigt, um die Peerings zu erstellen, sowie um den gerouteten Traffic in den Cluster zu bekommen. Diese LIFs unterscheiden sich nur in der Service Policy (default-route-announce) von anderen LIFs.
cl1::> network interface create -vserver cl1 -lif bgp1 -service-policy default-route-announce -home-node cl1n1 -home-port a0a-100 -address 10.91.0.61 -netmask-length 24
cl1::> network interface create -vserver cl1 -lif bgp2 -service-policy default-route-announce -home-node cl1n2 -home-port a0a-100 -address 10.91.0.62 -netmask-length 24Nach Anlegen dieser LIFs gibt es nun zwei neue „virtuelle“ Ports im Cluster, auf die später die LIFs der SVMs gelegt werden können, sowie eine neue Broadcast Domain namens Vip:
cl1::*> network port show -port v*
Node: cl1n1
Ignore
Speed(Mbps) Health Health
Port IPspace Broadcast Domain Link MTU Admin/Oper Status Status
--------- ------------ ---------------- ---- ---- ----------- -------- ------
v0a Default Vip up - -/- healthy -
Node: cl1n2
Ignore
Speed(Mbps) Health Health
Port IPspace Broadcast Domain Link MTU Admin/Oper Status Status
--------- ------------ ---------------- ---- ---- ----------- -------- ------
v0a Default Vip up - -/- healthy -
2 entries were displayed.
Erstellen der eBGP Peerings
Als Nächstes müssen die Peerings zu den Routern aufgebaut werden. Dazu dienen im ONTAP sogenannte Peer-Groups. Davon müssen wir in unserem Fall 4 Stück anlegen (fully-meshed), denn wir möchten ja nicht, dass z. B. bei Ausfall eines Routers die IP-Adressen auf den anderen Node schwenken müssen.
cl1::*> bgp peer-group create -ipspace Default -peer-group cl1n1-sw1 -bgp-lif bgp1 -peer-address 10.91.1.253 -peer-asn 65001
cl1::*> bgp peer-group create -ipspace Default -peer-group cl1n2-sw1 -bgp-lif bgp2 -peer-address 10.91.1.253 -peer-asn 65001
cl1::*> bgp peer-group create -ipspace Default -peer-group cl1n1-sw2 -bgp-lif bgp1 -peer-address 10.91.1.254 -peer-asn 65001
cl1::*> bgp peer-group create -ipspace Default -peer-group cl1n2-sw2 -bgp-lif bgp2 -peer-address 10.91.1.254 -peer-asn 65001Nun sollten wir auf dem Router auch schon die BGP Sessions sehen (der State der Peers ist nicht mehr Idle, aber es werden auch noch keine Routen ausgetauscht, wie man an der 0 in der Spalte State/PfxRcd sehen kann):
sw1# show ip bgp summary
BGP summary information for VRF default, address family IPv4 Unicast
BGP router identifier 10.91.1.253, local AS number 65001
BGP table version is 202, IPv4 Unicast config peers 3, capable peers 3
2 network entries and 2 paths using 336 bytes of memory
BGP attribute entries [4/544], BGP AS path entries [2/12]
BGP community entries [0/0], BGP clusterlist entries [0/0]
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
10.91.0.61 4 65042 3 4 3 0 0 2d 0
10.91.0.62 4 65042 3 4 3 0 0 2d 0
10.91.1.254 4 65001 12 12 3 0 0 2d 1Erstellen eines LIFs für CIFS
Nun erstellen wir ein LIF und announcen seine IP-Adresse über BGP. Dazu dient das Flag -is-vip true beim network interface create Kommando. Sobald wir dieses Flag angeben, müssen wir auch keine Netzmaske mehr angeben: VIP LIFs werden immer als /32 announced.
cl1::> network interface create -vserver MD1 -lif cifs2 -is-vip true -address 10.91.42.147 -home-node cl1n1 -home-port v0a -service-policy default-data-files
cl1::> network interface show -vserver MD1 -lif cifs*
Logical Status Network Current Current Is
Vserver Interface Admin/Oper Address/Mask Node Port Home
----------- ---------- ---------- ------------------ ------------- --------- ----
MD1
cifs1 up/up 10.92.4.202/16 cl1n1 a0a-1092 true
cifs2 up/up 10.91.42.147/32 cl1n1 v0a true
2 entries were displayed.Dieses LIF wird nun per BGP von Node 1 announced, und die Route ist auf dem Switch in der BGP Routingtabelle sichtbar:
sw1# show ip bgp summary
BGP summary information for VRF default, address family IPv4 Unicast
BGP router identifier 10.91.1.253, local AS number 65001
BGP table version is 202, IPv4 Unicast config peers 3, capable peers 3
2 network entries and 3 paths using 336 bytes of memory
BGP attribute entries [4/544], BGP AS path entries [2/12]
BGP community entries [0/0], BGP clusterlist entries [0/0]
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
10.91.0.61 4 65042 828387 828263 202 0 0 3w2d 1
10.91.0.62 4 65042 828375 828263 202 0 0 3w2d 0
10.91.1.254 4 65001 828958 828934 202 0 0 1y30w 2
sw1# show ip route 10.91.42.147
IP Route Table for VRF "default"
'*' denotes best ucast next-hop
'**' denotes best mcast next-hop
'[x/y]' denotes [preference/metric]
'%<string>' in via output denotes VRF <string>
10.91.42.147/32, ubest/mbest: 1/0
*via 10.91.0.61, [20/0], 20:15:46, bgp-65001, external, tag 65042
Wenn wir nun das LIF auf den Node 2 verschieben, so wird das sofort über BGP auf den Routern übernommen:
cl1::> network interface modify -vserver MD1 -lif cifs2 -home-node cl1n2
cl1::> network interface revert -vserver MD1 -lif cifs2sw1# show ip bgp summary
BGP summary information for VRF default, address family IPv4 Unicast
BGP router identifier 10.91.1.253, local AS number 65001
BGP table version is 205, IPv4 Unicast config peers 3, capable peers 3
2 network entries and 3 paths using 336 bytes of memory
BGP attribute entries [4/544], BGP AS path entries [2/12]
BGP community entries [0/0], BGP clusterlist entries [0/0]
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
10.91.0.61 4 65042 828393 828268 205 0 0 3w2d 0
10.91.0.62 4 65042 828381 828268 205 0 0 3w2d 1
10.91.1.254 4 65001 828964 828941 205 0 0 1y30w 2
sw1# show ip route 10.91.42.147
IP Route Table for VRF "default"
'*' denotes best ucast next-hop
'**' denotes best mcast next-hop
'[x/y]' denotes [preference/metric]
'%<string>' in via output denotes VRF <string>
10.91.42.147/32, ubest/mbest: 1/0
*via 10.91.0.62, [20/0], 00:00:10, bgp-65001, external, tag 65042
Fazit
Warum das alles? Der Vorteil von BGP ist gerade in größeren Netzwerken nicht von der Hand zu weisen, zum Beispiel in einem MetroCluster Konstrukt. Dort wurde bisher immer ein „flaches“ Layer-2 Netzwerk über beide Standorte benötigt, da die IP-Adressen einfach nur innerhalb der Layer-2 Broadcast Domain verschoben wurden. Mit BGP ist die Layer-2 Netzwerkkonfiguration nun komplett irrelevant, da die IP-Adressen ja in beliebigen AS announced werden können.
Die Konvergenzzeiten (Umschaltzeiten) sind, zumindest in unseren Lab-Versuchen, ähnlich schnell, wenn nicht sogar schneller, als bei einem einfachen Layer-2 Konstrukt mit Gratuitous ARPs.
Allerdings ist der Aufwand, BGP zu konfigurieren und zu betreiben, nicht zu vernachlässigen. Daher empfiehlt es sich, das BGP Feature im ONTAP nur zu nutzen, wenn man bereits BGP im Rechenzentrum nutzt, oder dies zumindest ernsthaft in Erwägung zieht.
Die AU ist mehrfach ausgezeichneter NetApp- und Cisco-Partner und wir stehen gerne bei Projekten rund um das Thema NetApp ONTAP, Cisco Switching und Routing, u.v.m zur Seite.