
Dieser Artikel soll einen Einblick in eines meiner letzten Projekte geben und aufzeigen, was ein Protokollwechsel im Storage Bereich für „Folgen“ im Datacenter hat. Doch bevor wir anfangen, hier ein kurzer Überblick über die Hardwarekomponenten:
Bisherige Umgebung:
Cisco UCS Mini mit M5 Blades
FC Anbindung an Brocade Gen5 Switches
Netapp AFF A220 per FC (FC-SCSI)
VMware vSphere 7.x
Neue Umgebung:
Cisco UCS-X mit M7 Blades / UCSX-9508 / UCS-FI-6536 4.3(2.230129)
FC Anbindung an Brocade Gen7 Switches
Netapp AFF A250 per FC (FC-NVMe), ONTAP 9.13.1P6
VMware vSphere 8.0U2
Doch zum Start erstmal ein paar Impressionen aus dem RZ – was man ganz gut erkennen kann: Massive Bandbreite dank durchgehend 100GB und natürlich ein sauberes Cabeling für diese Anzahl an Server.

UCS-X Konfiguration
Die Konfiguration erfolgt wie bei UCS-X üblich über die Weboberfläche Cisco Intersight in der Variante als Intersight Connected Virtual Appliance. Die hier gezeigten Konfigurationsschritte beziehen sich nur auf die FC-NVMe relevanten Teile und stellen keine vollumfängliche Anleitung dar.
Zum Start ein paar Impressionen zum Umfang des Projektes. Es handelt sich um zwei Standorte mit jeweils einem FI-Pärchen pro Standort. Am Hauptstandort hatten wir 12 Blades zur Verfügung, wovon 8 Stück als ESXi-Host genutzt werden.
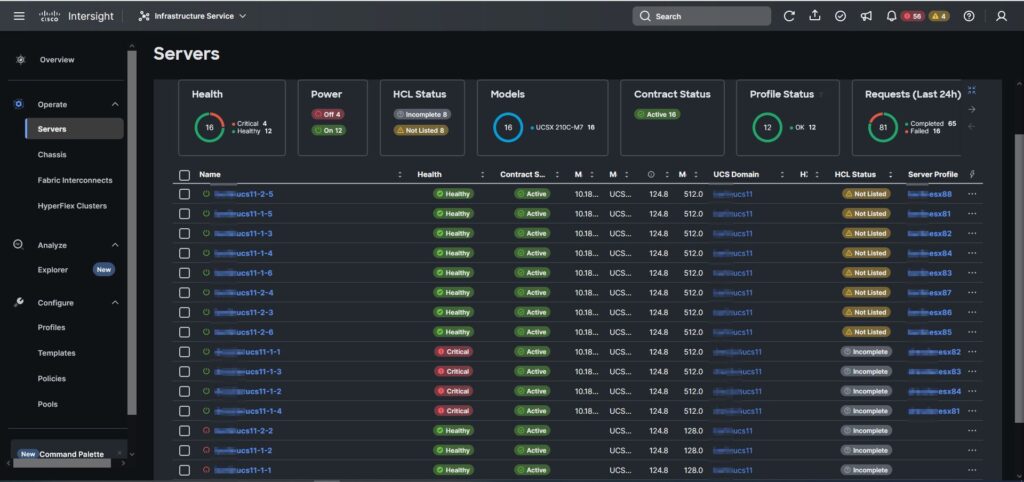
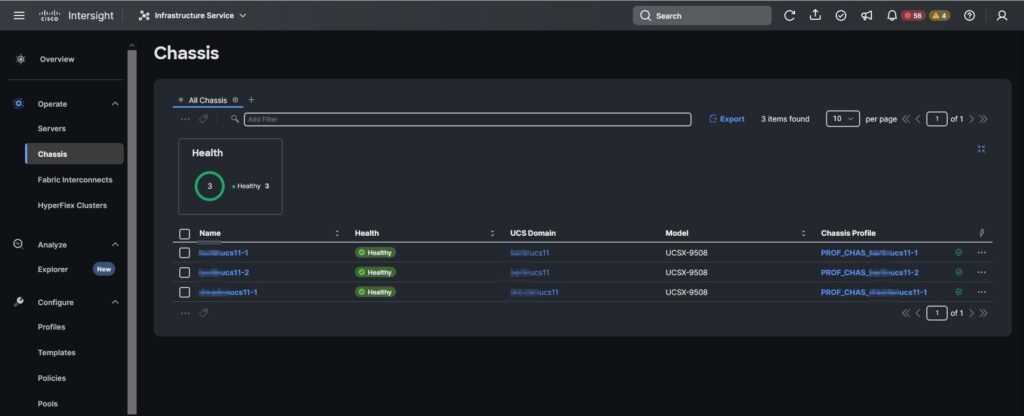
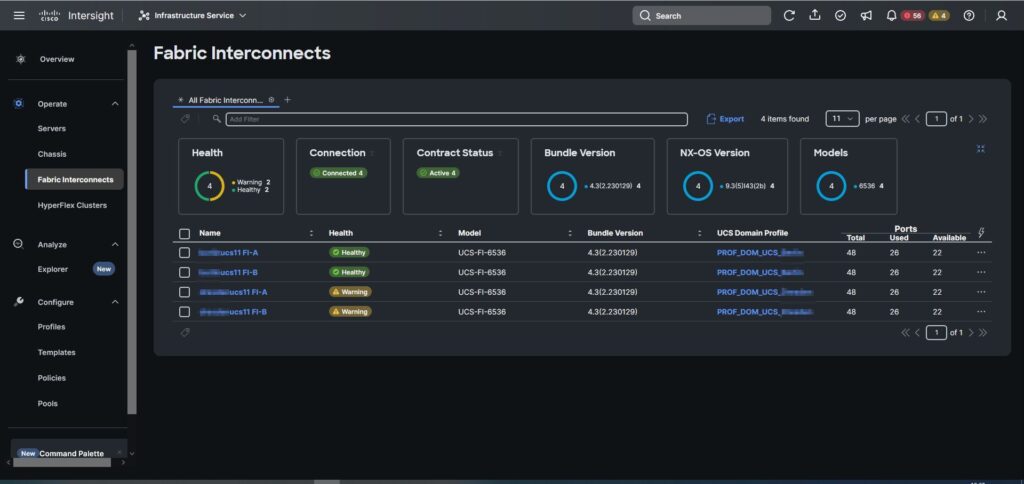
Ports 31& 32 wurden als Uplink Ports in die Kundeninfrastruktur genutzt. Ports 35 & 36 wurden mittels Breakout MPO Kabel an die FC Infrastruktur des Kunden angeschlossen.
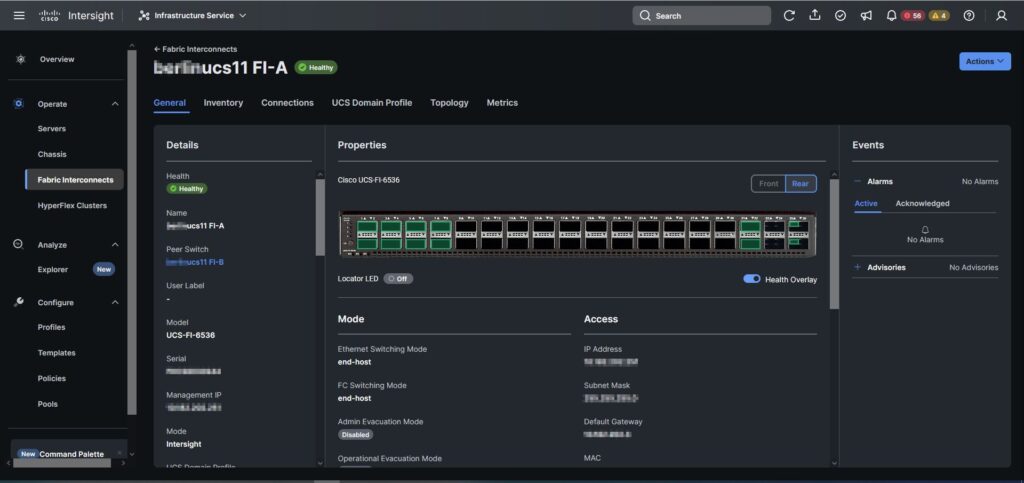
Für die ESXi-Blades wurden pro Standort separate Server Templates angelegt.
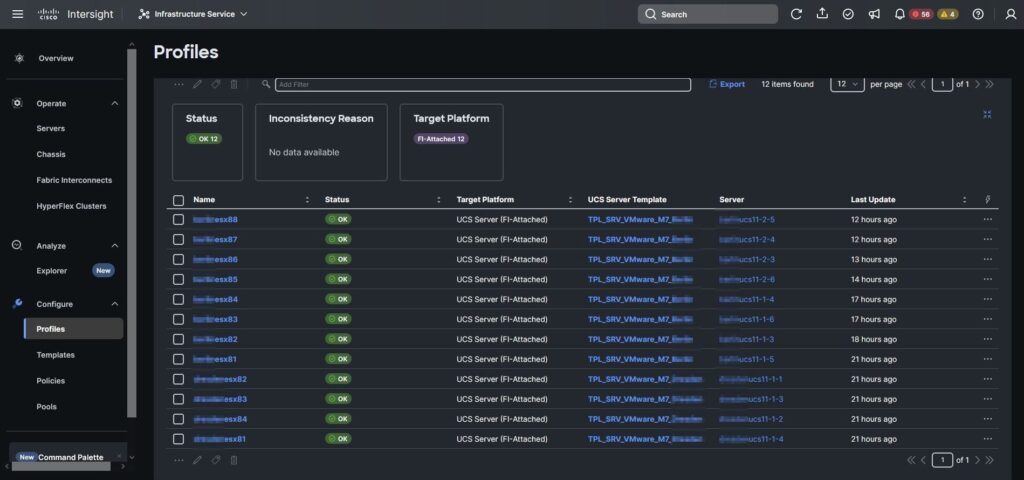
Den ersten „Aha-Moment“ hatten wir bei den virtuellen HBAs bzw. der SAN Connectivity Policy. Da die meisten aktuellen FC HBAs in den klassischen Rack Servern bzw. Switche in der Regel NVMe „Out-of-the-Box“ beherrschen, haben wir im ersten Moment die HBAs im UCS wie gewohnt angelegt. Das führte aber dazu, dass wir im ESXi-Umfeld keinerlei NVMe Settings am HBA gesehen haben. Nach kurzem Troubleshooting hatte sich herausgestellt, dass ein separater HBA Typ für NVMe im UCS benötigt wird.
Da wir in dieser Umgebung sowohl von FC booten, als auch die Datastores darüber angebunden werden sollen, haben wir uns entschieden, klassische HBAs für Boot und NVMe HBAs für die NVMe Datastores anzulegen.
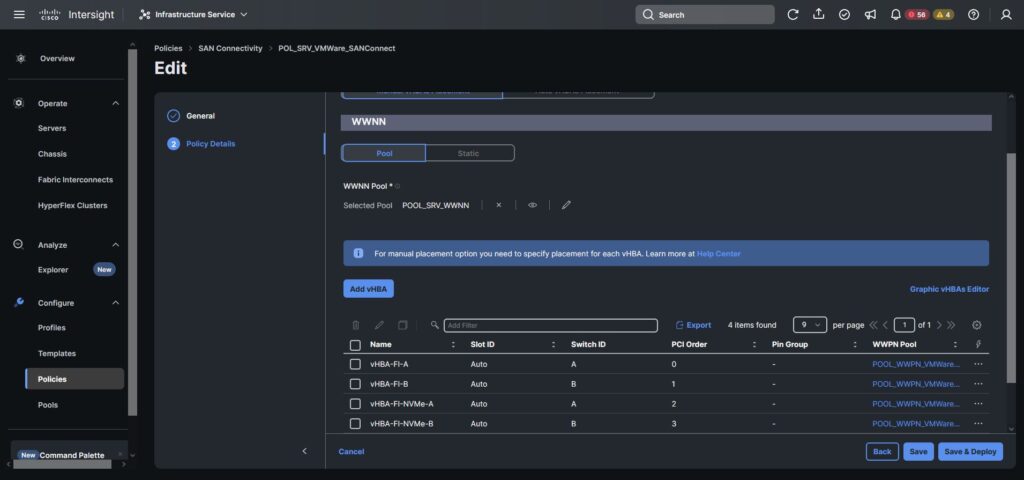
Innerhalb den HBA Settings sieht man dann auch den Unterschied. Hier haben wir „fc-nvme-initiator“ gewählt.
NetApp Konfiguration
Als NetApp kommt eine AFF A250 zum Einsatz, was deshalb besonders charmant ist, da man damit „End-to-End“ NVMe sprechen kann, weil auch entsprechende SSDs verbaut sind. Neben der Hardwareplattform, die NVMe als Frontend Protokoll unterstützen muss, muss dies auch der FC HBA tun. In ONTAP lässt sich das recht einfach prüfen:
cluster::> fcp adapter show -fields data-protocols-supported
(network fcp adapter show)
node adapter data-protocols-supported
------- ------- ------------------------
cl1n1 0c fcp
cl1n1 0d fcp
cl1n1 0e fcp
cl1n1 0f fcp
cl1n2 0c fcp
cl1n2 0d fcp
cl1n2 0e fcp
cl1n2 0f fcp
cl1n7 2a fcp,fc-nvme
cl1n7 2b fcp,fc-nvme
cl1n7 2c fcp,fc-nvme
cl1n7 2d fcp,fc-nvme
cl1n8 2a fcp,fc-nvme
cl1n8 2b fcp,fc-nvme
cl1n8 2c fcp,fc-nvme
cl1n8 2d fcp,fc-nvmeNodes n1 und n2 im vorhandenen 4-Node Cluster gehören zu einer AFF A220, welche kein FC-NVMe unterstützt, Nodes n7 und n8 gehören zur AFF A250, deren 32Gb FC-HBA Support für FC-NVMe bietet.
Auch wenn es mittlerweile technisch möglich ist, NVMe zusätzlich zu anderen Protokollen in einer SVM zu aktivieren, würde ich immer empfehlen, eine separate SVM anzulegen.
Die komplette Step-by-Step Anleitung für eine neue NVMe fähige SVM gibt’s hier.
vserver nvme create -vserver <SVM_name>
network interface create -vserver <SVM_name> -lif <lif_name> -service-policy default-data-nvme-fc -home-node <home_node> -home-port <home_port> -status-admin up
vol create -vserver <SVM_name> -volume <vol_name> -aggregate <aggregate_name> -size <volume_size>
vserver nvme namespace create -vserver <svm_name> -path <path> -size <size_of_namespace> -ostype <OS_type> -block-size 512B
vserver nvme subsystem create -vserver <svm_name> -subsystem <name_of_subsystem> -ostype <OS_type>
vserver nvme subsystem host add -vserver <svm_name> -subsystem <subsystem_name> -host-nqn <Host_NQN>
vserver nvme subsystem map add -vserver <svm_name> -subsystem <subsystem_name> -path <path>Nach kurzer Umgewöhnung der Syntax geht das Ganze auch locker von der Hand, aus LUNs werden Namespaces und aus IGroups werden Subsystems. Wichtig zu wissen an dieser Stelle: Das Zoning, üblicherweise WWPN based Zoning, unterscheidet sich überhaupt nicht. Hier gilt weiter klassisches Single-Initiator-Zoning auf WWPN Basis.
VMware Konfiguration
In VMware sah das ganze erstmal unspektakulär aus, erwartungsgemäß sieht man hier 4 HBAs:
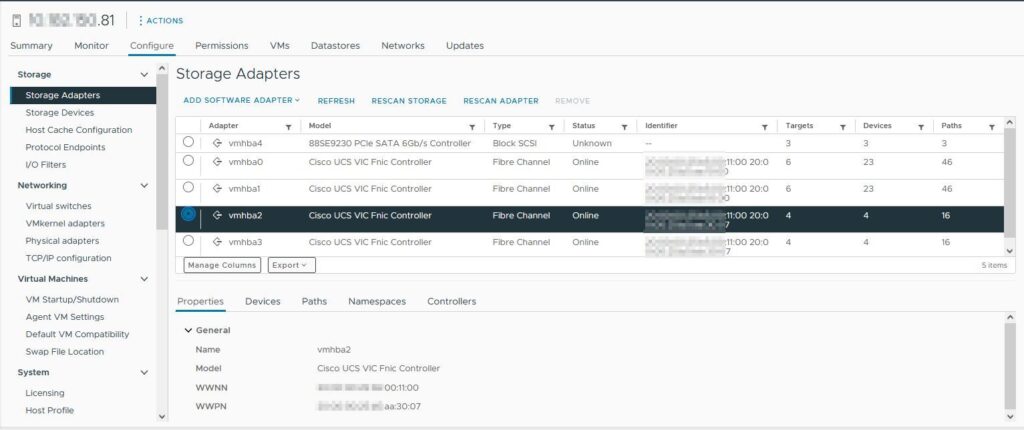
vmbha0/1 sind die traditionellen FC HBAs, vmhba2/3 die NVMe-FC HBAs.
Tipp: Bei solchen grundlegenden Änderungen an der virtuellen Hardware im UCS, z.B. der HBA Anzahl oder PCI Reihenfolge, einfach VMware neu installieren, das erspart später viel Ärger…
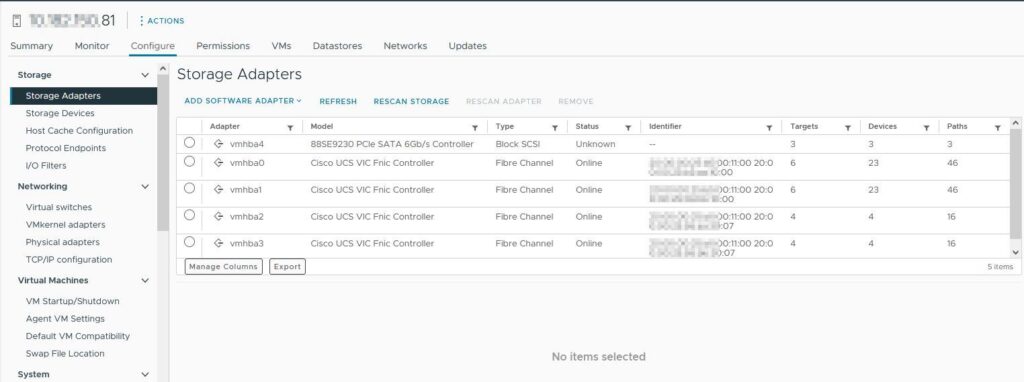
Klickt man jetzt auf die einzelnen HBAs werden die Unterschiede ersichtlich.
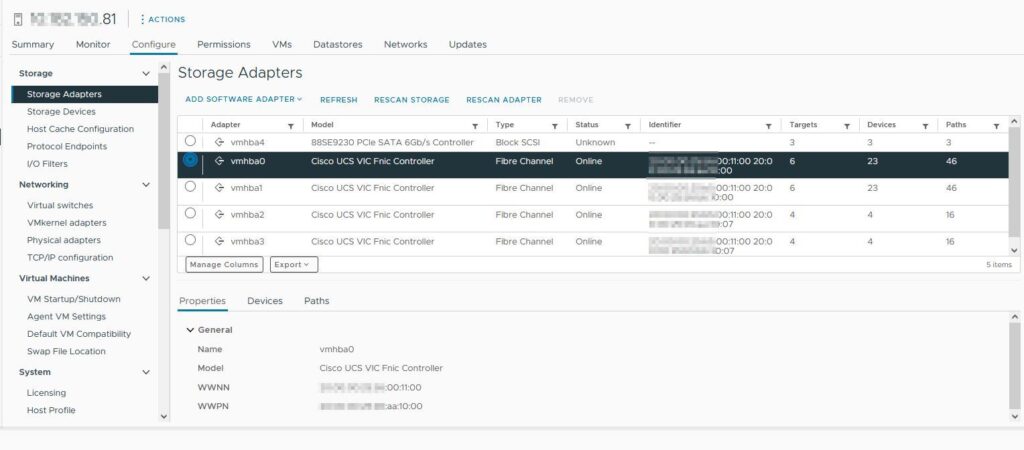
Beim NVMe HBA tauchen hier weitere Tabs auf wie z.B. Namespaces oder Controllers.
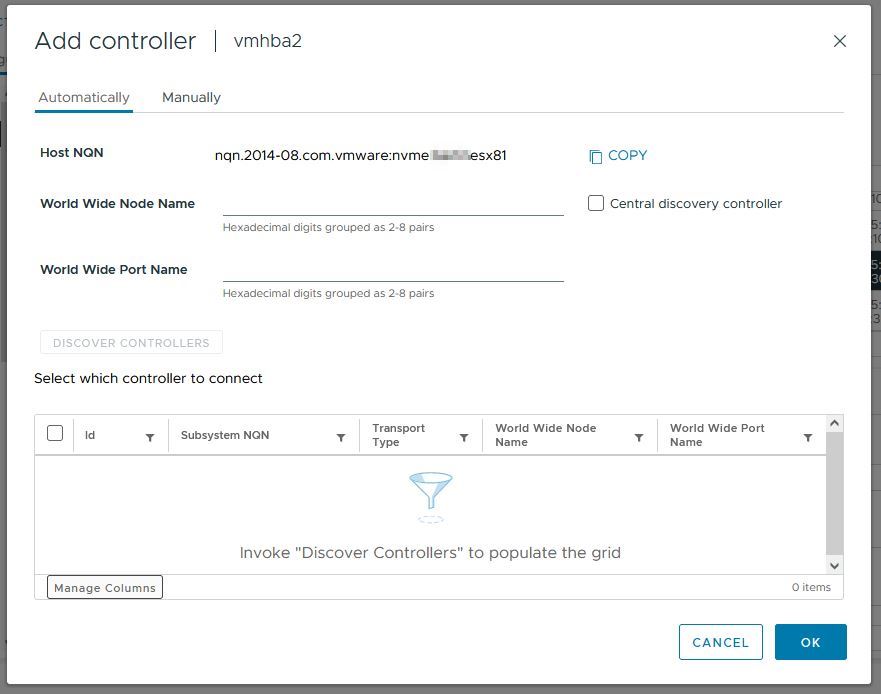
Für die Verbindung benötigt man einen sogenannten Host NQN (NVMe Qualified Name). Dieser wird aus dem FQDN des ESXi-Servers generiert – der FQDN sollte zu diesem Zeitpunkt bereits korrekt gesetzt sein. In vorherigen VMware Versionen gab es noch keinen Punkt in der GUI dafür und man musste die Info per esxcli abrufen. Das haben wir beim ersten Host auch so gemacht.
esxcli nvme info getBei allen weiteren ESXi-Hosts sind wir in der GUI auf Controllers und hier auf „Add controller“. Wir hatten nach dem Befehl auf der CLI bzw. dem Klick in der GUI immer Probleme, die Devices zu sehen und haben uns angewöhnt, nach diesem Schritt die Hosts durchzubooten, das hat zuverlässig funktioniert.
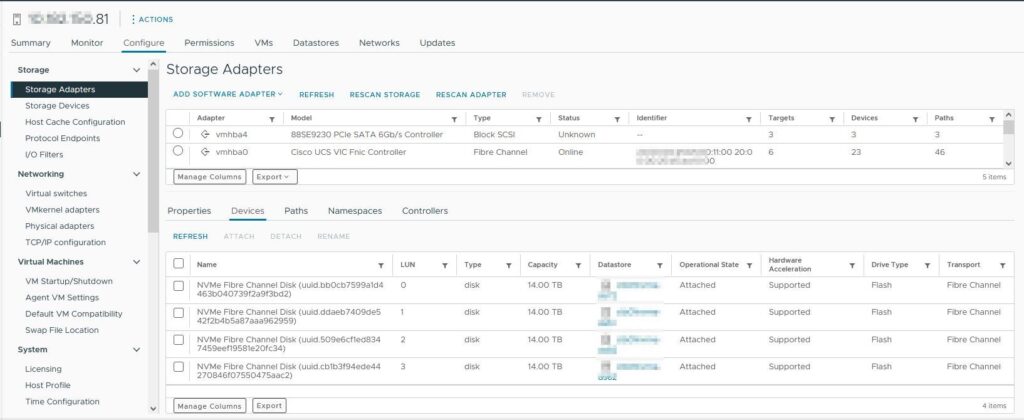
Mit einem Klick auf Devices sieht man auch die zuvor erstellten Namespaces.
Veeam Konfiguration
Der ein oder andere mag sich jetzt fragen – was hat Veeam damit zu tun? Soweit mal gar nichts, für Kunden allerdings, welche bisher Veeam mit NetApp SAN Integration genutzt haben, schon. Denn genau dieser Direct SAN Access Mode wird mit NVMe nicht mehr supported.
Im Veeam Forum gibts schon einen langen Thread dazu, wichtig dazu ist allerdings: Kein NVMe Storage am Markt wird aktuell supported. Bedeutet also klassisches Backup über den VMkernel Port mittels NBD.
Wie immer sehe ich so etwas mit einem weinenden und einem lachenden Auge: Einerseits muss auf eine sehr stabile und schnelle Integration verzichtet werden, andererseits reduziert das die Komplexität und es gibt mittlerweile einige Möglichkeiten, auch so schnell an die Backupdaten zu kommen.
Passend zum Projekt wurde die Veeam B&R Version 12.1.2.172 released. Hier gab es massive Verbesserungen für NBD, also den netzwerkbasierten Transportmodus, welche die Geschwindigkeit in der Praxis verdoppelt (auf unserem Blog gibt’s die Details). Diese Tatsache, in Kombination mit den durchgängigen 100Gb-Uplinks an den UCS FIs sorgt in der Praxis für eine sehr schnelle Datenübertragung, sodass die Umstellung zu verschmerzen war.
Noch ein kleiner Hinweis an dieser Stelle: Bereits seit vSphere 7.0U3 gibt es einen neuen VMkernel Port vom Typ „Backup“. Je nach Kundenumgebung lässt sich der Backup Traffic damit noch besser isolieren und je nach Netzwerk Setup auch beschleunigen. In der Veeam Community gibt’s einen guten Artikel dazu.
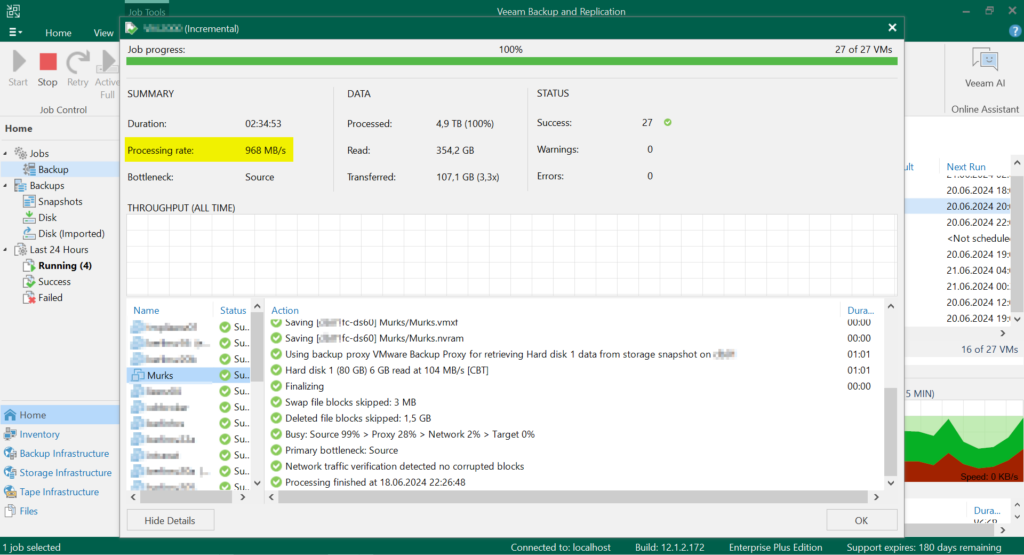
Abschließend ein Screenshot aus der Kundenumgebung vor der Umstellung, hier also noch mit Direct SAN Access. In diesem Fall wurden die Daten also noch mit 2x16GB direkt vom Storage abgeholt.
Wie in jedem Techniker schlummert auch in mir ein Spielkind, also wollte ich mal Testen wie die Geschwindigkeit nach der Umstellung mit „nur noch“ NBD ist. Der Traffic läuft jetzt nur noch über Netzwerk, genauer gesagt über die VMKernel Ports der ESX Hosts.
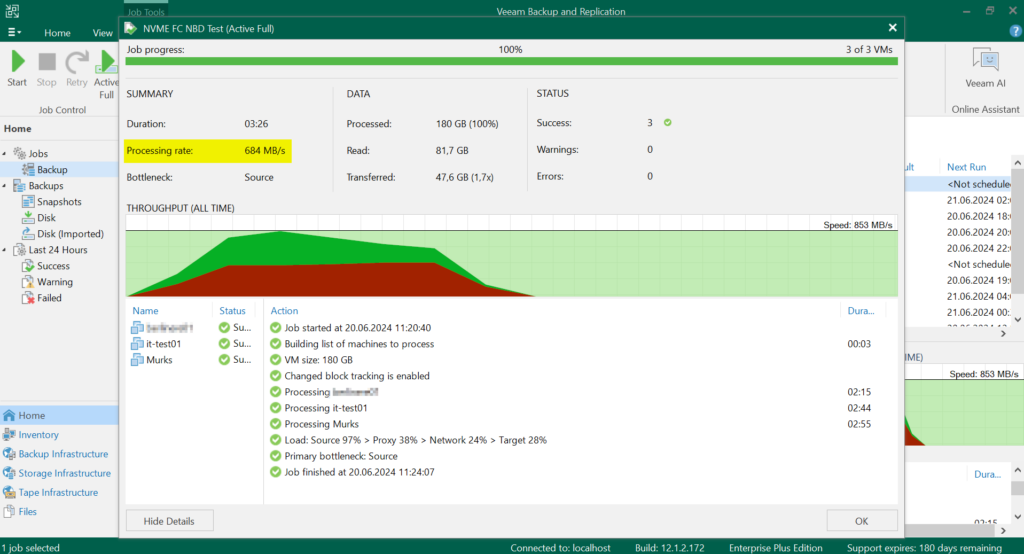
Fazit: Für mich völlig in Ordnung, es waren nur drei kleinere VMs, mit mehr Parallelität lässt sich hier sicherlich noch mehr rausholen, das klare Limit wird ohnehin die 10Gb-Schnittstelle des Backup Servers sein.